
Googleの新しい順位決定方法のすべて。SEO関係者必読、グーグル特許出願文書全訳
United States Patent Application: 0050071741(合衆国特許出願0050071741)には、Googleのスコア付け・ランク付けに関する技法について詳細に描かれている。ここでわかるのは、履歴データをもとにして、スパムを検出したり、時事的に求められている文書を上位表示させたりする技法が採用されているということである。
最近のGoogleでは、今までのSEO(サーチエンジン最適化)技術を使ってもいきなり順位が落ちたりする現象が知られていた。その理由がこの特許出願文書をよく読むことによって理解できるのではないかと思われる。
小手先のSEOや、スパムが力を持つ時代はすでに終わっている。SEOに興味のある人は、無差別トラックバックやコメントスパムもかえってマイナスであることをよく理解していただければと思う。
やはり「優れた内容を、整理された形でわかりやすく」提供することこそが最強のSEOとなりつつある。
この記事のリンク用URL| ≪ 前の記事 ≫ 次の記事
| コメント(3) | トラックバック(22)

 (旧:
(旧:
 )
)
概要・主張を省略。原文はUnited States Patent Application: 0050071741。
■関連した出願
[0001]この願書は、2003年9月30日に提出された合衆国臨時出願 No. 60/507, 617 に基づく35 U.S.C. sctn.119のもとで優先権を主張する。
■発明の背景
■[0002]1. 発明分野
[0003]当発明は一般に情報検索システムに関連しており、特に、少なくとも部分的には、関連する文書に結びつけられた履歴データに基づいて検索結果を生成するためのシステムと方法についてのものである。
■[0004]2. 関連技術の解説
[0005] World Wide Web (「ウェブ」)は膨大な量の情報を含んでいる。検索エンジンは、ウェブ文書の目録を作ることによって、ユーザーがこの情報の必要な場所を知ることを助ける。典型的には、ユーザーの要請に応え、検索エンジンは要請に関係ある文書へのリンクを返す。
[0006]検索エンジンは、ユーザーの関心が何であるかを決定するために、ユーザーから与えられた検索用語(検索クエリと呼ばれる)に基づいてもよい。検索エンジンの目的は、検索クエリに基づいて高品質の適切な結果へのリンクを見いだすことである。典型的には、前もって蓄えられたウェブ文書の集成資料に対して、検索クエリ内の用語と一致することによって、検索エンジンはこの目的を達成する。ユーザーの検索用語を含むウェブ文書は「当たり」とみなされ、ユーザーにその結果が返される。
[0007]検索エンジンは、ユーザーから与えられた検索クエリに応じて最も適切な結果をユーザーに提供するのが理想だ。1種類目の検索エンジンでは、文書に含まれる単語と検索クエリ内の用語の比較に基づいて、適切な文書を見つけ出す。もう一つの種類の検索エンジンでは、文書内に検索クエリの単語が存在しているかどうかということ以外に、あるいはそれに加えて、別の要素を使って適切な文書を見つけ出す。そのような検索エンジンの一例として、文書の相対的な重要性を決定するために、その文書へのリンクやその文書からのリンクと関連する情報を用いる。
[0008]どちらの種類の検索エンジンも、検索クエリに対して品質の高い結果を提供しようとしている。検索エンジンによって生み出された品質に影響を与えてもよいいくつかの要因がある。たとえば、若干のウェブサイト制作者は、意図的にランクを膨らませるスパム・テクニックを使う。同じく、「陳腐な」文書(すなわち、しばらくの間更新されず、新鮮みのないデータを含む文書)は「新入生」文書(すなわち、最近更新され、それゆえ、最近のデータを含んでいる文書)より高くランキングされてもよい。文脈によっては、陳腐な文書のランクが高いと、検索結果の質を落とすことになる。
[0009]それゆえ、検索エンジンによって作られた結果の品質を改善する必要が出てくる。
■発明の要約
[0010]この発明の原則に沿ったシステムや方法は、少なくとも部分的には、文書と結び付けられた履歴データに基づいて文書を採点してもよい。この採点は、検索クエリに関連して生み出された検索結果を改善するために使ってもよい。
[0011]この発明の原則に沿った一つの機能によって、文書を採点するための方法が提供される。この方法は、文書を特定し、そしてその文書と結びつけられた一つまたは複数の形式の履歴データを取得することが含まれてもよい。この方法は、少なくとも部分的には、一つまたは複数の形式の履歴データに基づいて、その文書のための採点を生み出してもよい。
[0012]もう1つの機能として、文書を採点するための方法が提供される。この方法は、リンクされた文書と結びつけられた連結データの年齢を決定し、連結データの年齢の減衰機能に基づいてリンクされた文書をランク付けすることが含まれてもよい。
■図解の簡単な説明
[0013]この明細書の一部に含まれている添付図解は、この発明の具体的表現を示したもので、解説とともにこの発明を説明するためのものである。図において、
[0014]図1は、この発明の原則に沿ってシステムや方法が実装されてもよいネットワークの模範図である。
[0015]図2は、この発明の原則に沿って実装される図1のクライアントやサーバーの模範図である。
[0016]図3は、この発明の原則に沿って実装される図1の検索エンジンの機能ブロックの模範図である。
[0017]図4は、この発明の原則に沿って実装される文書採点の過程の模範図である。
■詳細な解説
[0018]この発明の以下の詳細な解説は、添付図に言及している。別の図で同じ参照番号のものは、同じまたは似た要素であってもよい。また、以下の詳細な解説は、この発明を制限するものではない。
[0019]この発明の原則に沿ったシステムと方法は、たとえば、文書と結び付けられた履歴データを使って文書を採点してもよい。このシステムと方法は、採点結果を高品質の検索結果を提供するために使ってもよい。
[0020]ここで使われる用語「文書(document)」とは、機械で読み取れ、機械で保存できる作業上の生成物すべてのことである、と包括的に解釈されるべきである。文書には電子メール、ウェブサイト、ファイル、ファイル群、他のファイルへのリンクを埋め込まれたファイル、ニューズグループ投稿、ブログ、ウェブ広告などが含まれてもよい。インターネットでは、普通の文書がウェブページである。ウェブページには本文情報が含まれることが大半で、埋め込み情報(メタ情報、画像、ハイパーリンクなど)や埋め込み命令(Javascriptなど)が含まれてもよい。1つのページは1つの文書に対応してもよく、あるいは一つの文書の一部に対応してもよい。そのため、「ページ」と「文書」という単語は場合によっては同義であってもよい。あるいは、あるページには副文書のような文書の一部しか該当しなくてもよい。あるページは複数の文書に対応してもよい。
[0021]以下の解説では、文書は他の文書へのリンクや他の文書からのリンクを持っているものとして記されてもよい。たとえば、文書が別の文書へのリンクを含むとき、それは「前進リンク(forward link)」と呼んでもよい。文書が他の文書からのリンクを受けているとき、そのリンクは「バックリンク(back link)」と呼んでもよい。用語「リンク」が使われるとき、それはバックリンクや前進リンクのどちらについて言及していてもよい。
■ネットワーク配置の模式
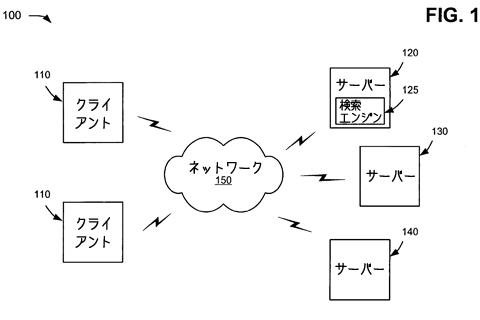
[0022]図1は、この発明の原則に沿ってシステムや方法が実装されてもよいネットワークの模範図である。ネットワーク100には、ネットワーク150経由で多数のサーバー120~140と接続した多数のクライアント110があってもよい。ネットワーク150には、ローカルエリアネットワーク(LAN)、ワイドエリアネットワーク(WAN)、PSTN(音声やデータの送受信のための国際的な電話システム)などの電話回線網、イントラネット、インターネット、記憶装置、別種のネットワーク、ネットワークの組み合わせなどが含まれてもよい。単純化するために、2つのクライアント110と3つのサーバー120~140が、ネットワーク150に接続しているということにしよう。実際は、さらに多く、あるいはより少ないクライアントとサーバーがあってもよい。また、クライアントがサーバーの機能を実行したり、サーバーがクライアントの機能を実行したりすることがあってもよい。
[0023]クライアント110は、クライアント・エンティティーを含んでいてもよい。エンティティーは、無線電話、パソコン、PDA、ラップトップ、その他のコンピューターや通信機器などの装置、これらの装置の一つで実装されるスレッドやプロセス、これらの装置の一つで実行可能なオブジェクトなどとして定義してもよい。サーバー120~140には、この発明の原則に沿った方法で文書を収集・処理・検索・維持するサーバー・エンティティがあってもよい。クライアント110とサーバー120~140は、有線・無線・光学式接続でネットワーク150に接続してもよい。
[0024]発明の原則に沿った実装において、サーバー120には、クライアント110によって利用できる検索エンジン125があってもよい。サーバー120は文書(たとえばウェブページ)の集成資料(corpus)をクロールし、文書に索引をつけ、クロールした文書の貯蔵庫に文書と関係づけられた情報を蓄積してもよい。サーバー130と140は、サーバー120でクロールされた文書を蓄積・保守してもよい。サーバー120~140は別々のエンティティーとして示されている。120~140の一つまたは複数のサーバーがサーバー120~140の他の機能のいくつかを行なうことができてもよい。たとえば、サーバー120~140のうち二つ以上が一つのサーバーに実装されることができてもよい。また、サーバー120~140のどれか一つが、二つ以上の別の装置に実装されることができてもよい。
■クライアント/サーバー・アーキテクチャーの模式
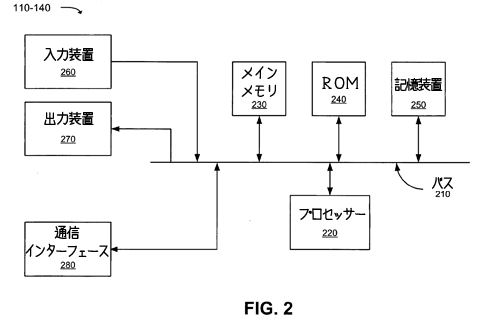
[0025]図2はクライアントまたはサーバー・エンティティー(以下「クライアント/サーバー・エンティティ」とする)の模式図である。これはクライアント110やサーバー120~140に対応していてもよく、発明の原則に沿った実装によるものである。クライアント/サーバー・エンティティーには、バス210、プロセッサー220、メインメモリ230、リードオンリー・メモリ(ROM)240、記憶装置(ストレージ・デバイス)250、一つまたは複数の入力装置260、一つまたは複数の出力装置270、通信インターフェース280があってもよい。バス210には、クライアント/サーバー・エンティティーの構成要素の間で通信ができるようにするコンダクターがあってもよい。
[0026]プロセッサー220には、命令を解析・実行する一つまたは複数の通常プロセッサーやマイクロプロセッサーがあってもよい。メインメモリ230には、ランダムアクセスメモリ(RAM)、あるいは、プロセッサー220によって実行される情報や命令を蓄える別種の動的記憶装置があってもよい。ROM 240には、従来のROM装置、あるいは、静的情報やプロセッサーによって使われる静的情報や命令を蓄える別種の静的記憶装置があってもよい。記憶装置250には、磁気や光学的な記録媒体とそれに対応するドライブがあってもよい。
[0027]入力装置260には、クライアント/サーバー・エンティティにオペレーターが情報を入力できるようにする一つまたは複数の通常の機器があってもよい。たとえばキーボード、マウス、ペン、音声認識、バイオメトリック装置などである。出力装置270には、オペレーターに情報を出力する一つまたは複数の通常の機器があってもよい。たとえばディスプレイ、プリンター、スピーカーなどである。通信インタフェース280は、クライアント/サーバー・エンティティーが他の装置やシステムと通信することができるようにするあらゆる機構であってもよい。たとえば、通信インターフェース280には、ネットワーク150のようなネットワーク経由で他の装置やシステムと通信する機能があってもよい。
[0028]下記に詳細を示すとおり、この発明の原則に沿ったクライアント/サーバー・エンティティーは、ある特定の検索関連の演算を行なう。クライアント/サーバー・エンティティーは、メモリ230のようなコンピューター読み取り可能な媒体に含まれるソフトウェア命令を実行するプロセッサー220への応答として、これらの演算を行なってもよい。コンピューター読み取り可能な媒体は、一つまたは複数の物理的・論理的記憶装置や搬送波と定義してもよい。
[0029]ソフトウェア命令は、データ記憶装置250のような他のコンピューター読み取り可能な媒体から、あるいは通信インタフェース280経由で他の装置から、メモリ230に読み込まれてもよい。メモリ230の中のソフトウェア命令によって、プロセッサー220は下記に示すようなプロセスを引き起こしてもよい。あるいは、この発明の原則に沿ったプロセスを実行するソフトウェア命令の代わりに、あるいはそれと一緒に、配線による電気回路を使ってもよい。それゆえ、発明の原則に沿った実装は、ハードウェア電気回路やソフトウェアの特定の組み合わせに限定されるものではない。
■検索エンジンの模式
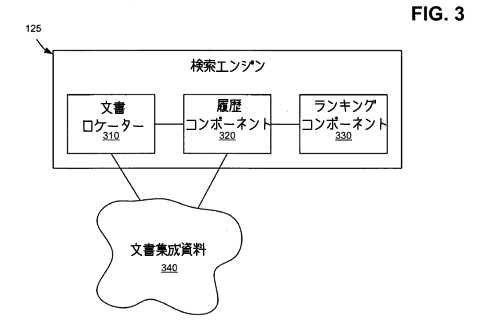
[0030]図3は発明の原則に沿った実装における検索エンジン125の機能ブロック・ダイアグラムの模式である。検索エンジン125には、文書ロケーター310、履歴コンポーネント320、ランキング・コンポーネント330が含まれてもよい。図3に示されるように、一つまたは複数の文書ロケーター310と履歴コンポーネントは、文書集成資料340と接続してもよい。文書集成資料340には、たとえば検索エンジン125でアクセス可能なデータベース内で以前にクロールされ、索引を付けられ、保存された文書関連情報が含まれてもよい。履歴データは、以下に詳細に記述するが、文書集成資料340のそれぞれの文書と結びつけてもよい。履歴データは、文書集成資料340またはほかのどこかに蓄えてもよい。
[0031]文書ロケーター310は、内容がユーザー検索クエリと一致する文書セットを見つけてもよい。文書ロケーター310は、ユーザーの検索クエリ内の用語を集成資料内の文書と比較することによって、文書集成資料340から文書を探し当ててもよい。一般に、検索された用語を含む文書群を返すために、文書に索引を付けたり、索引づけられた収集から検索したりするプロセスは、よく知られた技法となっている。したがって、文書ロケーター310のこの機能は、ここではこれ以上記述しない。
[0032] 履歴コンポーネント320は、文書集成資料340の文書と結びつけられた履歴データを集めてもよい。この発明の原則に沿った実装では、履歴データには、以下に関連するデータが含まれてもよい。文書取得日時、文書内容の更新/変化、クエリ分析、リンクに基づく判断基準、アンカーテキスト(すなわち、ハイパーリンクが埋め込まれているテキスト。文書中ではアンダーラインその他の方法で区別されていることが多い)、トラフィック、ユーザー行動、ドメイン関係情報、ランキングの履歴、ユーザーが維持/生成したデータ(たとえばブックマーク)、アンカーテキスト内の独特の単語・合字・句、独立した等価物への結びつき、文書の話題。これらのさまざまなタイプの履歴データについては、以下、詳細を記述することになる。他の実装では、履歴データは追加または別の種類のデータを含んでもよい。
[0033]ランキング・コンポーネント330は、文書集成資料340内の一つまたは複数の文書にランキング・スコア(ここでは単に「スコア」とも呼ぶ)を割り当ててもよい。ランキング・コンポーネント330は、検索クエリの質問よりも前に、あるいは独自に、あるいは関連して、ランキング・スコアを割り当ててもよい。文書が検索クエリと関係しているとき(たとえば検索クエリに関連があるものとみなされた場合)、検索エンジン125はランキング・スコアに基づいて文書を並び替え、検索クエリを送信したクライアントに、並び替えられた文書セットを返してもよい。この発明の機能に沿って、ランキング・スコアとは、文書の品質を数量化しようとした数値である。この発明の原則に沿った実装では、このスコアは少なくとも部分的には履歴コンポーネント320からの履歴データに基づいている。
(以下、続く。後半⇒Googleの新しい順位決定方法のすべて。SEO関係者必読、グーグル特許出願文書全訳2 [絵文録ことのは]2005/07/01)
- 【広告】★文中キーワードによる自動生成アフィリエイトリンク
この記事のリンク用URL| ≪ 前の記事 ≫ 次の記事
| コメント(3) | トラックバック(22)
(旧:
)
トラックバック(22)
長いので印刷というかプリントアウトして利用するか グーグル特許出願文書全訳 グー... 続きを読む
Googleのスコアリングと不変のSEO 続きを読む
最近知ったニュース、サイトなどのメモ。 意図したわけではないのだが、何故かGo... 続きを読む
ShortCut:言及なしトラックバックでGoogleページランクがダウン というようなことがあるようですが,このブログではしばらく静観の方向で。 こちらのエントリへの言及・リンクのないエン... 続きを読む
久々のブログ周り+Google関わりのビッグ(?)ニュースでした。... 続きを読む
言及のないトラックバックについてや、Googleの新しい順位決定方法について 続きを読む
とっても恐い話です。 blogをやっていると記事にトラックバックをもらうことがあるわけです。 自分の記事内容にきちんと触れて、文章中に言及リンク(この記事はここを参考に書... 続きを読む
言及リンクなしのTBを受けてるとGoogleのページランクが下がる、という記事を見かけます。 いろいろと調べてみると、いろいろな方が記事にされていますが、この噂の発端はこの記... 続きを読む
Googleの新たなアルゴリズム(ランキング手法)について 続きを読む
ことのはさんのところで出ている特許の翻訳が話題になっています。 Googleの新しい順位決定方法のすべて。 詳細まで読みきってないので、メモという位置づけまでですので、一般論です... 続きを読む
言及なしTBをはじくことについての色々。google云々は誤解です。そしてコメントへのお返事。 続きを読む
言及なしTBをはじくことについての色々。google云々は誤解です。そしてコメントへのお返事。 続きを読む
「絵文録ことのは 」さんのところで、Googleの新しい順位決定ついてのGoogleサイトの英文の訳や解説などが詳しく書かれていました。 Googleの新しい順位決定方法のすべて。SEO関係者... 続きを読む
Googleの新たなアルゴリズム(ランキング手法)について 続きを読む
言及のないトラックバックについてや、Googleの新しい順位決定方法について 続きを読む
SEOをされている方は、 例の件でgoogleが新たに特許を出願していた事は、 既にご存知の事でしょう。 今回は、 googleが出願した特許明細書の、 全訳をされた方がいらっしゃるので紹介... 続きを読む
「絵文録ことのは」さんより 〓松永さんのBLOGで最近のGoogleの順位決定方 続きを読む
今回はせっかくなんでアフィリエイトにも大切な、アクセスアップとリンクについてを初心者的に語ります!そしてトラックバックの倫理?について自分なりに語りまくります!トラック... 続きを読む
PageRank (ページランク) Counter: 1, today: 1, yesterday: 0 http://ja.wikipedia.org/wiki/PageRank ページ重要度の自動判定技術 PageRank は、 「多くの良質なページからリンクされているページは、や... 続きを読む
「絵文録ことのは」という松永英明さんが運営しているBlogに、Google社がpagerankの特許出願に使用した文書の日本語訳が掲載されています。記事... 続きを読む
ことのはさんのところで出ている特許の翻訳が話題になっています。 Googleの新しい順位決定方法のすべて。 詳細まで読みきってないので、メモという位置づけ... 続きを読む
Googleの新しい順位決定方法のすべて。SEO関係者必読、グーグル特許 ...を興味深く読ませていただきました。勉強になりました。 続きを読む
特許明細書の翻訳ですね。(ただし、特許明細書であって、特許ではないことは注意です)
私のもろ専門(記載内容もさらには技術分野もどんぴしゃ!(笑))
管理人さんのご存じのように、私は、この文書を作成する側にいます。
さらに技術分野もソフトウェア関連+機械関連です。
(上司はその関連(いわゆるBM関連)の第一人者だったりする(笑))
その観点から見る(米国の出願でベストモード規則の縛りがあるとしても)と、「『言及なしトラックバックでページランクが下がる』は間違い。」とは、必ずしも言えないんじゃないかな?と思います。
深く言及はしませんが、明細書を読む限り、そう言う方針で運営している可能性はありますね。それに、いたずらに権利範囲を狭くすることを書くとも思えません(作成側の思惑として)。
なので、「言及なしトラックバックでページランクが下がる」可能性もあるのでは?ということで、注意を喚起しておきたいと思います。
独占禁止法違反では?
アルゴリズムに独占権をつけられては何もプログラムできません。
独占禁止法違反では?
アルゴリズムに独占権をつけられては何もプログラムできません。